AI Bias/Data/Risk : Thoughtful Insights (Beware : Occasionally Counterintuitive !) : 3-day NIST RMF workshop
Three Days of nothing but AI Risk and Bias discussions ! 13 panels, ~50 speakers, more than 2000 registrants in slack channel ! The discussions were thoughtful, insightful, deep as well as engaging !
The panelists have in-depth knowledge, the moderators have done their preparations and the slack channel was lively — the hard work and thoughtfulness that went into the workshop is evident and appreciated.
After watching the videos and taking down notes (~22 pages!) plus reading the documents (RMF and the 1270), I think I understand (and appreciate) the framework a lot better.
FYI, I have a set of very interesting references at the end of this blog.
First, a quick background
There are two documents that are in the draft stage and discussed in the workshop.
1.The NIST AI Risk Management Framework: Initial Draft March 17, 2022
2.NIST Special Publication 1270 Towards a Standard for Identifying and Managing Bias in Artificial Intelligence. I had written a quick blog about this document [“AI Bias Detection — A New Normal from NIST”]. I will include salient notes into this blog.


Second, the caveats (& motivation)
These are my notes, covering the best practices and super interesting comments, leaving the gory details for you to watch the 3 day workshop [Here].
- My lens is towards pragmatic best practices we can use now (as well as good research references — listed in the last section below) — I needed to extract workable best practices for some documents we are working on — internally and externally.
- This nicely fits in with my notes from the FinRegLab/Stanford empirical paper on Machine Learning Explainability & Fairness [Here]
This is a slightly long blog (my notes are much longer!), but a must read for the ML Engineers, Data Scientists and, definitely for the Risk Professionals.
- And, when (… not if) you get a chance, watch the videos as well. As I was taking down notes (~22 pages!), took me lot longer — you will be able to go faster !! I also combed through the slack to extract interesting comments.
- Life will intervene, but be persistent !
If you are time challenged, at minimum take the time to go through the best practices and think about them. I have annotated them like so that you can scan and pick up the 42 (yep, 42 !) Best Practices while ignoring the rest!
Best Practice #0 : Scan & find all the 42 Best Practices in this blog !!
A word about the NIST work — the documents are “consensus-created, informative reference intended for voluntary use”. So, they are a little verbose and occasionally the creation-by-committee shows up.
Best Practice #1 : While they are in draft form, the NIST work and documents are extremely useful even today. They have put in a lot of good thinking, and it shows. So, incorporate the NIST work now into your practices and update as the NIST work progresses — you don’t have to wait until their work is done
Next, the (occasionally counterintuitive !) insights
BTW, the workshop was following the Chatham House Rule i.e. “participants are free to use the information received, but neither the identity nor the affiliation of the speaker(s), nor that of any other participant, may be revealed”, so all insights are anonymous — but of course, you know who you are !
1. Realities of AI systems
- “We can’t accurately predict the future yet a lot of our intuitions are designed as if we can !” As a result, we get amplification of inequalities e.g. recidivism systems for criminal justice.
- Ask “For whom does the system fail ?” Is it making “lucky people luckier and unlucky people unluckier” or is it making the reverse ?
- “The reason humans don’t interact with the explanations is because the explanations aren’t consumable to end users”
- Relying just on fairness tools are like flipping to the very end of the end of the book without actually considering what the plot is ! It is not a way to think about using the tools but what to think about when you are working on these topics as you use the tools
- It is difficult to place trust in the current healthcare system — “When a call for checkup comes, one wonders ‘Is it something that is in my best interest or someone else doing this because it is part of their business model ?’”
- “We are replacing a bureaucracy with an algorithm” — in a certain sense, the bureaucracy will have its own algorithm (though typically not completely explicit), so this seems like a matter of which algorithm would be more appropriate to use, as opposed to whether algorithms should be used at all !
- Debate on unfair vs unbiased — Assume for a minute that job applicants are decided by a random number generator. It is unbiased so we can’t complain; we will still feel bad because it is unfair and not morally legitimate !
- “We are assessing real-world ML systems like we are writing an academic paper, rather than measuring real impact of AI system and that just is not going to work”
- “I never want to hear about your rank on Kaggle (which is a data mining contest) or the 4th decimal digit of your AUC test — they are nearly irrelevant measures — consumers care about safety, legality and real-world performance”
- Benchmarking academic performance is important because that is the indicator of what comes next, but they might not be meant for real world performance
Best Practice #2 : Shift from measurement of performance on static tests on datasets, to measurements that reflect real world performance
Analyze every single failure point and analyze why the failure point happened rather than aggregate performance measures
It is not only the metrics but also the testing environment — the test results or as good or bad as the test environment [NIST-Workshop-0322]
Best Practice #3 : AI is neither built nor deployed in a vacuum, sealed off from societal realities of discrimination or unfair practices [NIST-1270]
Bias is neither new nor unique to AI and it is not possible to achieve zero risk of bias in an AI system. Bad pill to swallow but we should address the reality [NIST-1270]
Best Practice #4 : Think Risk tiering. No one has the resources to mitigate all of their risks, so we have to focus on the worst problems/sensitive uses [NIST-Workshop-0322]
- There are lots of principles — but the policy and practice side of AI Bias is still murky
- For example, Bias Mitigation is still untouched — Whom do we call when we see indications of negative impacts ? And, what do we do then ? What are the ways of increasing fairness ? So far NIST is silent — of course they are still in the initial stages
Best Practice #5 : For an organization to succeed in this space, you need to develop precise, concise and actionable best practices over principles and policy. e.g., “Bias Mitigation & Best Practices” identify best practices that your organization can draw to bring together all the different threads that are needed i.e., whom do we call & what do we do.
Best Practice #6 : Be incredibly specific on what you mean when you say AI is responsible. How does it actually look in practice ? Otherwise, the principles will be too broad that teams can disagree on how they interpreted those. Have well understood consequences (both positive and negative) and everyone from top to bottom agrees where the lines are drawn and the consequences of crossing them
There are mechanisms like Model Bias Score Card or similar mechanisms, but they need to be defined and transparently available [NIST-Workshop-0322]
- Another important aspect is the monitoring and measurement. “If you can’t measure it, you can’t improve it” — Lord kelvin
Best Practice #7 : Pay attention to monitor and measure the temporal and dynamic aspects, quantitative and qualitative assessment, and track risks related to an AI system and its impact across its lifecycle [NIST-Workshop-0322]
2. Data
- “Go where the data is,” creates a culture focused more on which datasets are available or accessible, rather than what dataset might be most suitable.
- We have to be careful to be fully “data driven” — we need to consider other aspects as well
Best Practice #8 : Question and be ready to defend data driven decisions … more precisely the data might not be qualified to make those decisions — focus on what data is suitable and should be used to train an AI system, rather than what is available.
Ask “Does this data represent the tasks that we would like a model to learn” [NIST-1270]
- The context of data defines how we think about or define data and as data moves between contexts it can become a different thing
- It is also important to ask “context for whom “— e.g., ML practitioners have a technical context; context construed technically need not be the same as the socio-technical context — “The nice thing about context is that everyone has it” — [context-seaver]
Best Practice #9 : Pay attention to and document the social descriptors when you scrape data from different sources. The context will be important later when we use the data for different purposes [NIST-Workshop-0322]
Best Practice #10 : “Data use/bias/performance is in the eye of the beholder ”. Remember, data doesn’t have an absolute view of reality; but it is the capture, collection and representation of data that brings the reality to the AI models [NIST-Workshop-0322]
- The general framing of context is to consider the genealogy of the modes of construction of the datasets (the choices, the intentions, the agendas, the values and the outcomes) and overlay onto the context
Best Practice #11 : Ask “Does the way dataset is constructed fit the socio-technical purpose ?” Not just if the dataset will give the accuracy.
Data sheets for datasets [datasheets-acm] and model cards [modelcards-acm] are a great way to fully understand the choices being made with regard to building responsible AI systems [NIST-Workshop-0322]
Best Practice #12 :To increase representativeness and responsible interpretation, include as many diverse viewpoints as practical (not just the experts) when collecting and analyzing specific datasets. And seek the most adequate solution for a given context [NIST-Workshop-0322]
Best Practice #13 : Sometimes we as a society misunderstand or confuse platform governance/business model with data governance. Be more transparent about how companies use data to create new products and services [NIST-Workshop-0322]
- Context is not just about the data (where and how it was collected) but where and how it is used. There is no easy way to characterize or measure and access context drift in data
Best Practice #14 : Be aware of the context drift in data i.e. where and how it is used and it’s appropriateness for that context. Context drift in data is inevitable, unless we have this uber dataset that fully captures a domain — past, present, and future!
Build data transparency mechanisms that give us more reflective interpretations of what kind of data are we hitting the model with. Many larger datasets are neither collected carefully nor curated at scale. This opportunistic data gathering, which is not curated to be a global snapshot, has the data drift built in.
Be aware that images that we are posting to our friends and family online are turning into a scientific object of inquiry [NIST-Workshop-0322]
3. Organizational — Multi-stakeholder working groups
It takes a village to develop AI models !!
Best Practice #15 : Multi-stakeholder Engagement & Impact Analysis is essential. Technology or datasets that seem non-problematic to one group may be deemed disastrous by others. Create a well-rounded diverse team bringing all kinds of different expertise and lenses to the work [NIST-1270]
Best Practice #16 : AI risk practice needs to be embedded in an organization not just the upper management or a risk group, it is a cultural shift. Also, it is evolving — neither all questions answered, nor all problems well understood. It has to be ingrained in the culture; checks and balances must be part of the pipelines [NIST-Workshop-0322]
Best Practice #17 : All parts of the organization should be involved in the AI risk practice. Provide multiple outlets and opportunities for all to raise their hands, ask questions and be involved in responsible AI [NIST-Workshop-0322]
Best Practice #18 : Have the tools, practices and put the incentive structure in place so that teams are incentivized to do the right thing i.e. pause, not to launch when something doesn’t meet certain criteria [NIST-Workshop-0322]
Best Practice #19 : Embrace iterative, continuous and evolving AI risk assessment process as part of organizational cultural shift i.e. seeing risk management as being beneficial to the organization
One way to building up that mindset and trust is through story telling. Just top-down directives might not be effective [NIST-Workshop-0322]
Best Practice #20 : Continuous improvement is important — consider an internal audit function that occasionally not only measures adherence to written policies and procedures but also recommends changes to those policies and procedures, to improve the organization’s risk posture [NIST-Workshop-0322]
4. AI Systems & Risk
- AI systems bring positive outcomes which organizations balance with traditional risks. But different stakeholders have different opinions on what risks to include in the NIST RMF (as well as in real life). In any case, the risks can’t be netted
Best Practice #21 : Consider the positive and not so positive outcomes of AI. But don’t net them — AI risk mitigation is not a quantitative balance but an interdisciplinary qualitative judgement. And don’t be afraid to veto a deployment due to potential unintended consequences [NIST-Workshop-0322]
Best Practice #22 : While there are many approaches for ensuring the technology we use every day is safe and secure, there are factors specific to AI that require new perspectives.
There is a general view that there needs to be a “higher ethical standard” for AI than for other forms of technology. Also from a public perspective, Bias is tightly associated with the concepts of transparency and fairness in society [NIST-1270]
- Additionally, “risk to what” and “which risk to whom” and “who is accountable for those risks and harms” is complex, broad and evolving. For example, with the EU AI act, the ultimate risk is to the fundamental rights of the inhabitant citizens
5. Humans quickly anthropomorphize machines
- Soldiers have named IED robots and been sad when they are destroyed. Simplistic robotic dogs can help people in nursing homes feel comforted, even when they know the “dog” is just a machine.
Best Practice #23 : Beware of anthropomorphism. We also acquiesce individual and organizational responsibilities as we anthropomorphize the “system”.
Often the reply-back on questions and concerns is “…well the system is doing it …”. There is a pass-the-buck with a lack of knowledge that “we are the system”. Here this bias is towards lack of awareness of systems and processes, the underlying transparency.
6. AI Systems, Fairness & Bias
- The plethora of fairness metric definitions illustrates that fairness cannot be reduced to a concise mathematical definition. [21-fairness-def-1], [21-fairness-def-2]
- It would seem that “math is standing in our way in achieving justice” ! But that is not what is happening. We have many definitions of fairness which sound intuitively and morally appealing because they capture different normative values and perspectives.
- Maybe it is “treating similar people similarly” or in other places it is “people who should look similar might look dissimilar in this moment because they have they had less educational opportunities in the past (and if you give them a chance they will prove themselves)”. These kind of normative are captured and reflected in these mathematical definitions
- Fairness impossibility theorems — “if you have two or more definitions of fairness, you cannot prove they are fair at the same time in most realistic cases. You might be able to prove equality in edge cases”
Best Practice #24 : Fairness is dynamic, social in nature, application and context specific — not just an abstract or universal statistical problem. Also, the point is not that we have a lot (of definitions) but which one is appropriate for the use case at hand [NIST-Workshop-0322]
Best Practice #25 : The technical fairness definitions don’t give us don’t give us any kind of escape route from having those very difficult normative debates. What the map does is allows us to make those debates more precise and make the tensions very clear [NIST-Workshop-0322]
Best Practice #26 : There are many stakeholders and it is difficult to satisfy all of them at the same time. The good news is that when we take the context into consideration these decisions get a little bit easier [NIST-Workshop-0322]
Best Practice #27 : Ask “For whom does the system fail ?” But remember it is a finite question. It can’t give a realistic answer for auditing ridiculously large models ! The feasibility of comprehending what they are doing is impossible. [NIST-Workshop-0322]
Organizing consequence scanning workshops might be a good practice, because they are quite helpful to start asking the question of what the intended and unintended consequences are.
Play a Rawlsian philosophical ethical game of “if I were this person what would I be worried about?”. Goes a long way in avoiding mistakes that we see in the world of algorithmic bias
Best Practice #28 : Ethics cannot be automated or a-priori. Even the same algorithm used in slightly different context will end up having different kinds of monitors (and fairness metrics) because they have different kinds impacts on humans [NIST-Workshop-0322]
Best Practice #29 : In addition to the normal computational bias, consider human and systemic biases [NIST-1270]
NIST 1270 identifies 3 categories of AI bias and the challenges for mitigating bias.

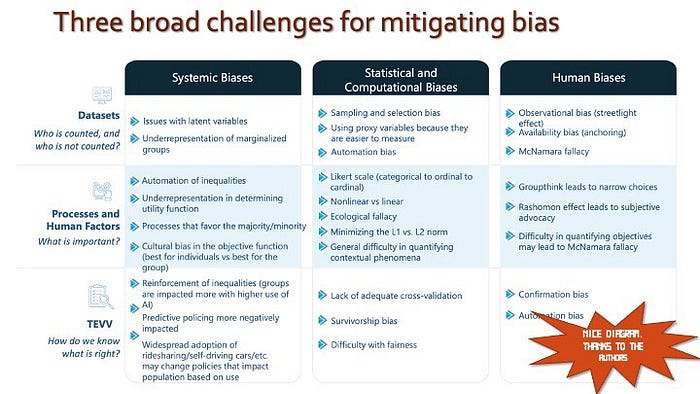
7. Uncertainty in AI Systems
NIST 1270 identifies two broad classes of uncertainty — Epistemic and Aleatoric uncertainty.
- Epistemic uncertainty, also known as systematic uncertainty, refers to deficiencies by a lack of knowledge or information. This may be because the methodology on which a model is built neglects certain effects or because a particular data has been deliberately hidden.
- For example, LLMs (Large Language Models) create significant challenges e.g. relying on large amounts of un-curated web data increases aleatoric uncertainty
- Aleatoric uncertainty, also known as statistical uncertainty, refers to unknowns that differ each time we run the same experiment. It refers to the variability in the outcome of an experiment which is due to inherently random effects in the data and the process
Best Practice #30 : To mitigate the risks stemming from epistemic and aleatoric uncertainties, model developers should understand the sources and other details about data as well as work closely with the organizations deploying them [NIST-1270]
- Just because can’t put up enough fire alarms doesn’t mean we shouldn’t put up any fire alarm — meaning even for large models we should have monitors even though we know that they will not be comprehensive.
Best Practice #31 : We have to do what we can do, while being aware that there are questions that are still unanswerable at this point. So be flexible, adaptive, and open to changes [NIST-Workshop-0322]
The fallacy of inscrutability[inscrutability-2] is interesting.
Best Practice #32 : Code is not the right level of abstraction at which awe should try to understand AI systems, whether is for accountability or adaptability; rather we need to understand these systems in terms of their inputs and outputs, their overall design, the values that are embedded into the software and how the software system fits in as part of the overall institution that is deploying it [inscrutability-2]
8. Human/Societal Values as a measure of AI Systems
Best Practice #33 : In the future, while a lot of the focus in on accuracy and performance is necessary, societal impacts will be an important metric to evaluate AI Models. We might have to tone down the accuracy for societal reasons [NIST-1270]
Best Practice #34 : Be aware and prepare for societal value implications to triumph computational/accuracy metrics to evaluate an AI Model; this will become a regulatory policy [NIST-1270]
- The NIST 1270 wants us to understand AI as a socio-technical system, acknowledging that the processes used to develop AI technologies are more than their mathematical and computational constructs.
- Their point-of-view on what is missing from current remedies (transparency, datasets, and test, evaluation, validation, and verification (TEVV)) is guidance from a broader SOCIO-TECHNICAL perspective that connects these practices to societal values.
- Representing these complex human phenomena (socio-technical systems) with mathematical models comes at the cost of disentangling the context necessary for understanding individual and societal impact and contributes to a fallacy of objectivity
Best Practice #35 : Expand your perspective beyond the machine learning pipeline, to recognize and investigate how AI systems are both created within and impacts our society [NIST-1270]
- Value Sensitive Design is a discipline that AI system designers can follow to explore, understand and incorporate human values into AI systems
- Values do not exist in isolation. They sit in a very delicate balance with each other. So, if we pick up on privacy, we are likely to pick up on trust and security; if we pick up on dignity then identity, agency and others will also be affected.
- The values exist in tension with each other, balancing each other; so, it is not the removal of value tensions that we should thrive for, but rather to find the sweet spots that provide a balance among them, with the idea that they will shift over time i.e., design for dynamic balance
- The core theoretical constructs of VSD are the tripartite methodology
- 3 types of investigation that need to be engaged iteratively and integrated throughout — conceptual investigations (working definitions of values, ask about the stakeholders), empirical work (go out and find out) and technical (what we build tools technology, infrastructure and policy)
Best Practice #36 : Follow the principles and methodology of Value Sensitive Design. We have to engage in the complexity in which people experience values and technology in their lived lives. Engage values holistically not in isolation i.e. one value at a time (e.g., privacy by design, trust by design) won’t work [NIST-Workshop-0322]
9. Human in the loop — what will it solve ?
- The story of human-AI collaboration is not so straightforward
- When we put AI and humans, we make certain assumptions including mutual independence; but people might not interact with an AI system in the way we think they will
- The essence of socio-technical systems is that the combination of social and technical systems is not the sum of the two parts i.e. you can’t say an algorithm is better at these things and a human is better at those other things and so by combining them we can get the better of both worlds
- The practice of human-in-the loop also shifts the accountability to the front-line individuals instead of the people who developed the systems
- The belief that we will make better decisions if we get better advice is wrong. In reality even when we get good advice, sometimes we don’t follow it if it doesn’t align with our previously held beliefs
Best Practice #37 : Extreme brilliance, in AI systems, are indistinguishable from extreme stupidity. So, in the context of AI-assisted decision making where AI is expected to exceed the capability of the human operator, we can’t have both. They can’t oversee the AI (i.e., scrutinize its recommendation) and at the same time be ready to accept novel insights from the system (trust the system without scrutiny)
Best Practice #38 : People see explanations as sign of competence i.e. a system capable of providing explanations is more competent and so I am going to believe it rather than engaging cognitively with that content (i.e. overlaying their expertise)
Add cognitive forcing function i.e., modified the interaction such a way that people have to reflect on their own choice and the choices made by the AI -it reduced over reliance, but at the cost of decreased usability
- Informed and equitable decisions about the level of trust need to be at an institutional level. Often human in the loop is justifying the deployment of an algorithm that shouldn’t be deployed in the 1st place, may be because of documented concerns — errors, bias, opportunity to be used in an unintended manner and so forth !
Best Practice #39 : If you have concerns about some aspect of an algorithm, don’t justify deploying it by adding human in the loop. Think of determination of trust at an institutional level
- It is too early to say what can be generalized and what should be context specific. So don’t overly rely on proxy tasks to evaluate an algorithm
Best Practice #40 : Construct evaluation tasks that best mirror the real-world setting (even if you are not working with experts but normal laypeople on platforms like the mechanical turk or other crowdsourcing platforms), the types of interactions and the types of decisions the end users are making.
The evaluations should demonstrate, not whether an algorithm is accurate or even whether people understand the algorithm, but when you integrate the algorithm into a human decision-making process does that alter or improve the decision and the resultant decision making process — evaluate according to the downstream outcome
Best Practice #41 : In terms of training, many of the “user error” can be avoided by better interaction design. Secondly, we need more training on data-driven decision making on how to reason about synthesized data (where the systems look directly at a lot of data and surface insights) rather than training on AI or how to operate in AI-systems
Best Practice #42 : Think about the entire decision-making system not just the algorithm on its own — because even if an algorithm satisfies the criteria of fair or accurate (to the extent that we can show those things) and deemed not risky, it still can have downstream consequences when you put it into practice with human interactions
There are three types of Human Oversight (interaction) :
- In the loop (every transaction)
- On the loop (only for pre-defined events/exceptions)
- In command (less intervention during operations, rather during design, assessment, spot checks, etc.)
Lastly, the the References
I am keeping them here for my reference as well — it will take time to go through them and understand in detail. I have extracted some best practices as I read them … will update as I cover more …
- [NIST-RMF-0322] The NIST RMF, March 12, 2022 [Here]
- [NIST-1270] The NIST 1270, March 2022 “Towards a Standard for Identifying and Managing Bias in Artificial Intelligence” [Here]
- [NIST-Workshop-0322] The Agenda for the panels workshop 2, March 2022 [Here]
- Evaluation Gaps in Machine Learning Practice https://arxiv.org/abs/2205.05256
- Dissecting racial bias in an algorithm used to manage the health of populations https://www.science.org/doi/10.1126/science.aax2342
- An FDA for Algorithms http://www.administrativelawreview.org/wp-content/uploads/2019/09/69-1-Andrew-Tutt.pdf
- NISTIR 8330 has a section on trust in AI medical diagnosis. https://www.nist.gov/publications/trust-and-artificial-intelligence
- https://www.morganlewis.com/blogs/sourcingatmorganlewis/2021/03/recap-bias-issues-and-ai
- === Panel 10 : Who and what gets counted? Contextual requirements for datasets
- https://www.cell.com/patterns/fulltext/S2666-3899(21)00184-7?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2666389921001847%3Fshowall%3Dtrue
- https://journals.sagepub.com/doi/pdf/10.1177/20539517211040759
- https://www.cigionline.org/publications/listening-to-users-and-other-ideas-for-building-trust-in-digital-trade/
- https://www.cigionline.org/publications/could-trade-agreements-help-address-the-wicked-problem-of-cross-border-disinformation/
- https://www.cigionline.org/publications/listening-to-users-and-other-ideas-for-building-trust-in-digital-trade/
- https://www.cigionline.org/publications/could-trade-agreements-help-address-the-wicked-problem-of-cross-border-disinformation/
- https://www.cigionline.org/publications/data-dangerous-comparing-risks-united-states-canada-and-germany-see-data-troves/
- https://www.fpa.org/ckfinder/userfiles/files/8_AI%202020.pdf
- https://www.cigionline.org/articles/data-minefield-how-ai-prodding-governments-rethink-trade-data/
- “Data and its (dis)contents: A survey of dataset development and use in machine learning research” https://arxiv.org/abs/2012.05345
- https://odsc.medium.com/20-responsible-ai-and-machine-learning-safety-talks-every-data-scientist-should-hear-dea3de368c0c
- https://odsc.com/speakers/imagenet-and-its-discontents-the-case-for-responsible-interpretation-in-ml/
- Paradigm for a Comprehensive Approach to Data Governance https://sites.tufts.edu/digitalplanet/files/2021/11/DataGovHub-Paradigm-for-a-Comprehensive-Approach-to-Data-Governance-Y1.pdf
- [context-seaver] https://www.semanticscholar.org/paper/The-nice-thing-about-context-is-that-everyone-has-Seaver/0c12d07c850fc8ccf0076300fab3f6fbd9d9a96b
- [datasheets-acm] Datasheets for Datasets (ACM publication — arXiv is reference in Pub): https://cacm.acm.org/magazines/2021/12/256932-datasheets-for-datasets/fulltext
- [modelcards-acm] Model Cards for Model Reporting: http://dl.acm.org/citation.cfm?doid=3287560.3287596
- You Can’t Sit With Us: Exclusionary Pedagogy in AI Ethics Education https://dl.acm.org/doi/10.1145/3442188.3445914
- == Panel 11 : Context is everything
- [21-fairness-def-1] 21 definitions of fairness and their politics https://shubhamjain0594.github.io/post/tlds-arvind-fairness-definitions/
- [21-fairness-def-2] Tutorial: 21 fairness definitions and their politics
- [inscrutability-1] The fallacy of inscrutability https://www.researchgate.net/publication/328292009_The_fallacy_of_inscrutability
- [inscrutability-2] https://royalsocietypublishing.org/doi/full/10.1098/rsta.2018.0084
- https://www.protocol.com/policy/ftc-algorithm-destroy-data-privacy
- Trustworthy Machine Learning and AI Governance by Kush Varshney Trustworthy Machine Learning and AI Governance by Kush Varshney from IBM
- There is no tradeoff between accuracy and fairness in the construct space. https://proceedings.mlr.press/v119/dutta20a.html
- Paper on humble trust: https://philpapers.org/rec/DCRHT
- Can You Tell? SSNet — A Biologically-Inspired Neural Network Framework for Sentiment Classifiers — https://link.springer.com/chapter/10.1007/978-3-030-95467-3_27
- When people try to understand nuanced language they typically process multiple input sensor modalities to complete this cognitive task. It turns out the human brain has even a specialized neuron formation, called sagittal stratum, to help us understand sarcasm. We…
- Trustworthy Machine Learning — http://www.trustworthymachinelearning.com/
- IBM Research AI FactSheets 360 — http://aifs360.mybluemix.net/
- IBM Research Uncertainty Quantification 360 — http://uq360.mybluemix.net/
- UQ360 is an open source toolkit that can help you estimate, understand and communicate uncertainty in machine learning model predictions through AI application lifecyle
- AI Fairness 360 — http://aif360.mybluemix.net/
- AI Privacy 360 — http://aip360.mybluemix.net/
- AI Explainability 360 — http://aix360.mybluemix.net/
- The Shame Machine Reviewed in the New York Times — https://cathyoneil.org/
- Fairness and Machine Learning: Limitations and Opportunities — https://fairmlbook.org/
- Irreproducibility in Machine Learning — https://reproducible.cs.princeton.edu/
- Mitigating Dataset Harms Requires Stewardship: Lessons from 1000 Papers — https://arxiv.org/pdf/2108.02922.pdf
- Semantics derived automatically from language corpora contain human-like biases — https://www.science.org/doi/full/10.1126/science.aal4230
- == Panel 12 : Design Approaches for AI: Keeping Human Values and Ethics at the Core of AI Design
- Value Sensitive Design: Shaping Technology with Moral Imagination https://mitpress.mit.edu/books/value-sensitive-design
- Salesforce Ethical AI Maturity Model : Salesforce Trailhead (free online learning platform) mix of Ethical & Inclusive Design modules trailhead.salesforce.comtrailhead.salesforce.com
- Salesforce Trusted AI
- == Panel 13 — Is a human in the loop the solution?
- https://dl.acm.org/doi/10.1145/3377325.3377498
- http://www.eecs.harvard.edu/~kgajos/papers/2021/bucinca2021trust.shtml
- http://www.eecs.harvard.edu/~kgajos/papers/2022/gajos2022people.shtml
- https://www.microsoft.com/en-us/research/publication/designing-ai-for-trust-and-collaboration-in-time-constrained-medical-decisions-a-sociotechnical-lens/
- https://www.nature.com/articles/s41398-021-01224-x
- eecs.harvard.edu
- To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-Assisted Decision-Making
- People supported by AI-powered decision support tools frequently overrely on the AI: they accept an AI’s suggestion even when that suggestion is wrong. Adding explanations to the AI decisions does not appear to reduce the overreliance and some studies suggest that it might even increase it. Informed by the dual-process theory of cognition, we posit that people rarely engage analytically with each individual AI recommendation and explanation, and instead develop general heuristics about whether and when to follow the AI suggestions. Building on prior research on medical decision-making, we designed three cognitive forcing interventions to compel people to engage more thoughtfully with the AI…
- eecs.harvard.edu
- Do People Engage Cognitively with AI? Impact of AI Assistance on Incidental Learning
- When people receive advice while making difficult decisions, they often make better decisions in the moment and also increase their knowledge in the process. However, such incidental learning can only occur when people cognitively engage with the information they receive and process this information thoughtfully. How do people process the information and advice they receive from AI, and do they engage with it deeply enough to enable learning? To answer these questions, we conducted three experiments in which individuals were asked to make nutritional decisions and received simulated AI recommendations and explanations. In the first experiment, we found that when people were presented with bo…
- Designing AI for Trust and Collaboration in Time-Constrained Medical Decisions: A Sociotechnical Lens — Microsoft Research
- Major depressive disorder is a debilitating disease affecting 264 million people worldwide. While many antidepressant medications are available, few clinical guidelines support choosing among them. Decision support tools (DSTs) embodying machine learning models may help improve the treatment selection process, but often fail in clinical practice due to poor system integration. We use an iterative, […]
- Nature
- How machine-learning recommendations influence clinician treatment selections: the example of antidepressant selection
- Translational Psychiatry — How machine-learning recommendations influence clinician treatment selections: the example of antidepressant selection (552 kB)
- https://www.nature.com/articles/s41398-021-01224-x
- http://www.jennwv.com/papers/hilfr.pdf
- http://www.jennwv.com/papers/disaggeval.pdf
- http://www.jennwv.com/papers/intel-chapter.pdf
- http://www.jennwv.com/papers/intel-chapter.pdf
- http://www.jennwv.com/papers/manipulating.pdf
- http://www.jennwv.com/papers/interp-ds.pdf (edited)
- https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3921216
- papers.ssrn.compapers.ssrn.com
- The Flaws of Policies Requiring Human Oversight of Government Algorithms
- Policymakers around the world are increasingly considering how to prevent government uses of algorithms from producing injustices. One mechanism that has become
- https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3921216
- Digital Medicine — Do as AI say: susceptibility in deployment of clinical decision-aids (190 kB) https://www.nature.com/articles/s41746-021-00385-9
- Professor Ghassemi’s research (evil v. good AI; prescriptive v. descriptive) https://mitibmwatsonailab.mit.edu/people/marzyeh-ghassemi/ https://vectorinstitute.ai/team/marzyeh-ghassemi/
- https://arxiv.org/ftp/arxiv/papers/2109/2109.00484.pdf
