Generative AI GuardRails : Functional & Compositional Perspectives, to address the Enhanced Threat Surface
The current crop of Generative AI systems (like ChatGPT and Llama 2) are “fantastic beasts” if you can find them, tame them and abide by their idiosyncrasies. But they also have a dark side — they hallucinate, they can be misled, and they deliver the most rhetoric answer, neither profound or expert.
These tools aren’t truth-tellers, but smooth-talking stochastic Parrots !
My blog [Here]
This is a quick blog on how to think about Generative AI guardrails — an expansion of my earlier blog [Here]
Update : I knew it, I knew it, I knew it !! Usually I keep a blog on ice for a couple of days for it to marinate … even before this blog was published, The White House AI Executive Order came out - validating a few of my predictions and the importance of guardrails ! More later …
Of course, the devil is in the gory details …
We will ponder from two perspectives — the functional (i.e., the what) & then the compositional (i.e., how to compose an LLM pipeline using these guardrail components)
Complementary, but slightly different & completes the understanding …


Diving in … the full functional view below … we will focus on parts of it
I found a way to do the focus effect in Powerpoint ! A delicate dance between shape-merge-fragment-recolor-format. The artistic-blur doesn’t work in the Mac version ….
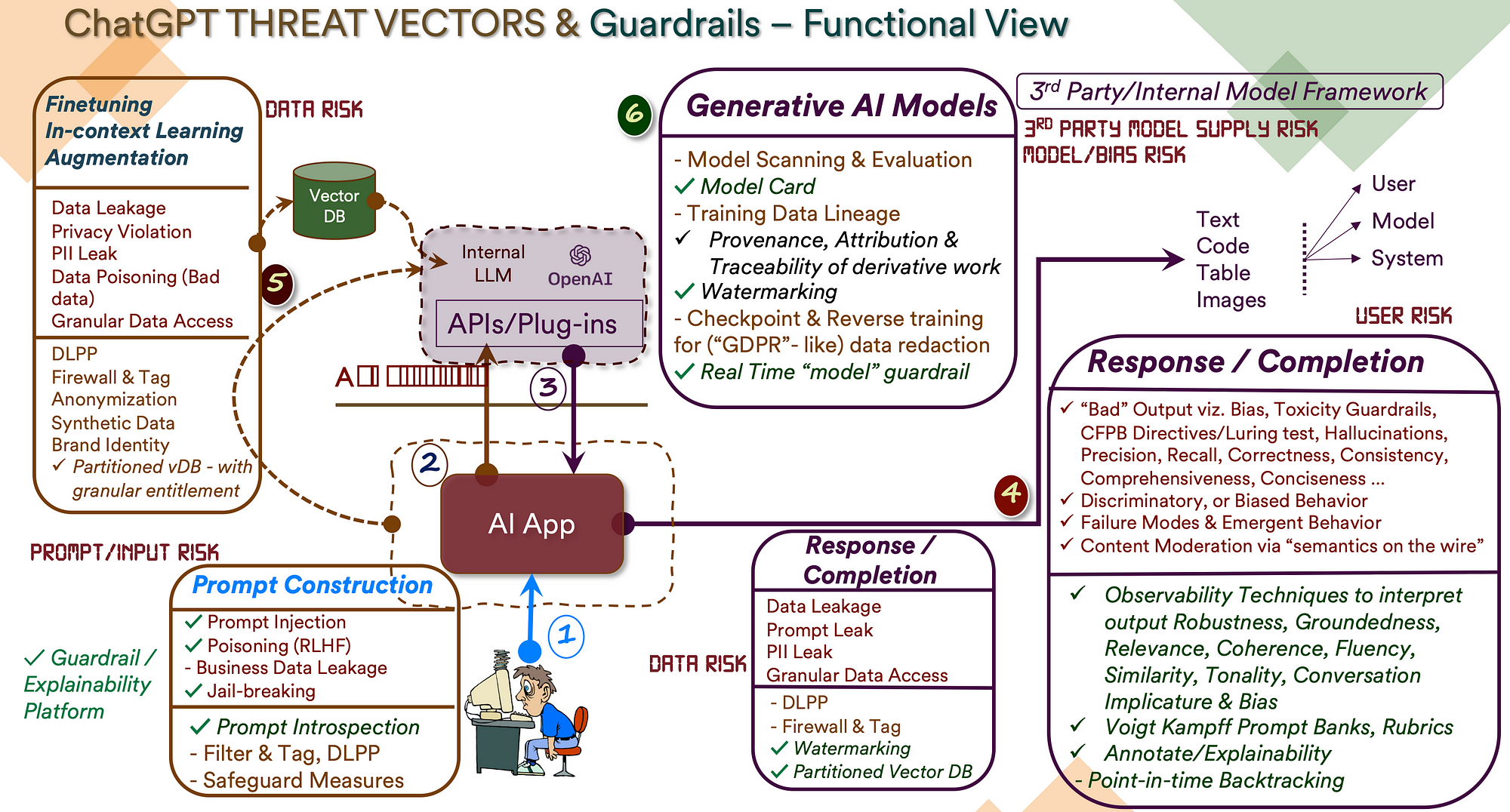
1. Prompt Construction

The various prompt injection vulnerabilities are new to the Generative AI world. But, of course, we have precedences like the SQL Injection to learn from. One important additional threat is the ability to extract sensitive information — be they LLM internals, corporate confidential or PII.
2. Response Analysis

The output from LLMs have their own challenges. The normal threats like problematic language generation, bias et al apply here as well. But due to the probabilistic nature, we have very different failure modes and more importantly emergent behaviors. And, they can hallucinate !
Take a look at the results from the Def Con 31 GRT (Generative AI Red Teaming) [Here]
Of course, we do want the “interesting” behaviors, but that depends on the context. Sometimes we want responses that are grounded on truth but with interesting view points; othertimes we want just facts
The source attribution is another dimension that is still emerging. I had written a quick blog [Here]
3. Model-specific vulnerabilities

As you might have observed, the categorization is not precise, simply because we can’t clinically separate the LLM from it’s outputs. But still, there are things we need to address at the output level and there are things we need to think about at the LLM system level.
- Bias in the LLM world is very different from Bias in the ML world; there is no decision boundary to point out and compare against different groups ! The manifestations are subtle and broader — things like conversation implicature and tonality might be bias factors !
- Explainability is another nuanced concept. When you think about it, you’ll realize that explainability and things like source attribution might be related, but there are mechanics and mechanisms from ML explainability world that are still relevant in the LLM world.
- Watermarking is another area that is developing; I think there will be a regulatory guidance on water marking — might even be mandatory to watermark AI generated responses. On a slightly different note, I am not convinced that Content provenance can be achieved by watermarking — a topic for another blog … Remember, the beauty of an LLM is that it can generalize and improvise — meaning, it has to forget the individual roots and forgoe backtracking …
- Red Teaming is one of the important tools for assessment and recommend risk mitigation strategies. (Update : With the WH AI Executive Order, the Red Teaming artifacts have taken a more strategic role). I have written about the Def Con 31 GAR (Generative AI Red Teaming) [Here] — very eye opening. Red Teaming artifacts include prompt banks (Voigt-Kampff anone ? — my blog [Here]), rubrics and even bad LLMs to test against.
Update:
I had completed the blog and teeed up to be published tomorrow. Even before the blog was published, The White House AI Executive Order came out today morning, (somewhat) mandating Watermarking (as well as sharing/escrow of Red Teaming Results) — which I had predicted !!!
Taking a quick detour, The White House AI Executive Order is interesting in many ways (Thanks to Shamik Kundu and Gary Marcus).
- They found a way to layer over existing laws and frameworks rather than a new AI Law
- It spans U.S. Government procurement “heft to drive traction in a messy space” — so has a large addressable market
- It is focused on “here and now”, “addressing today’s mundane challenges before addressing tomorrow’s existential ones like AGI” (I have a blog coming up on AGI)
- The order requires that comanpies developing ‘’foundational models” are subject to the requirements — so not all users of Generative AI. This makes sense-otherwise there would be scramble. I am sure inductry regulators will make some part of the executive order mandatory — which was my point all along !
Back to the feature presentation …
There is one more important component — the RAG i.e., Retrieval Augmentation. It is easier explained from the compositional perspective…
4. Compositional Perspective
One might think of the Gen AI pipeline as a ping to an LLM API like so.

- But, we all know that it is a lot more complex than that — even the following diagram is an over simplification

We have discussed most of the components — the pipeline has added DLPP, proxies et al to complete the defense mechanisms — against new and old threats. Plus, we have slotted them at the right place i.e., prompt introspection at the input, augmentation at both sides, bias and watermarking at the response side et al.
The new component is the augmentation framework with the contextual data, embedding et al + feeding into the retrieval components as well as the watermarking and the entitlement (the green lines below — believe it or not, there is a method to the color coding madness !).
The idea (of an augmentation platform) is three fold:
- A scalable augmentation infrastructure to take care of the “*ilities”
- Consistent, contextual, content across the enterprise that can be reused across multiple LLMs
- A refined granular entitlement to prevent data leakage across LLMs.

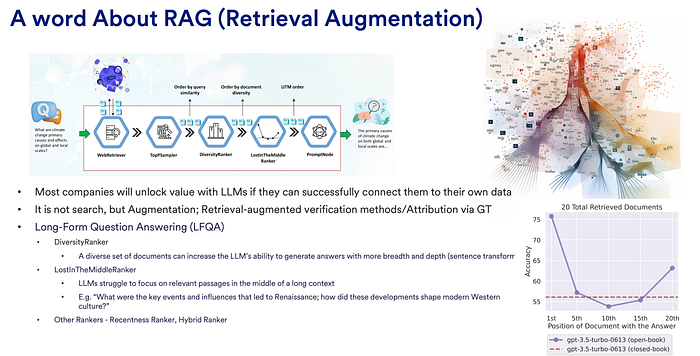
5. Retrieval Augmentation — A Detour
I will end this blog with a detour ! The following diagram perfectly explains the RAG !

The augmentation adds external context to the LLM knowledge. Interestingly it can also be used a part of the guardrails for verification and fact checking … and for in-context source attribution !
And, RAG is not just for searching, it has more conceptual applications … I like the lost-In-The-Middle concept and the use of RAG … more to come …
To get you started, I have been curating the vast amount of information in a set of GitHub repositories at https://github.com/xsankar/Awesome-Awesome-LLM. WOuld appreciate your insights …


